
Is there an observer-independent time-reversal in physics? Only for Hamiltonian dynamics, we argue. Otherwise there’s only retrodiction, which of course depends on the retrodictor’s (prior) believes. The paper (co-authored with Clive C. Aw and Valerio Scarani) is freely available from AVS Quantum Science website, where it is highlighted as a Featured Article. Below is a talk I recently gave on these ideas.
Overview on the Petz transpose map
I was recently invited to give an overview talk on Petz’s “transpose” or “recovery” map at the workshop Workshop on Quantum Information and Quantum Black Holes, organized by Norihiro Iizuka (Osaka) and Tomonori Ugajin (Kyoto). I’ve put together what I came to learn about the properties of Petz’s transpose map, its uses is various areas of information theory and physics, and (most importantly!) its conceptual meaning. Slides are available here. Mark Wilde’s textbook contains a chapter entirely devoted to the technical aspects of Petz’s map and the theory of approximate recoverability.
2025/4/22 Update: in these four years, we’ve learned a lot more about the Petz transpose map, especially its interpretation and relationship to Bayesian inversion. I’ve thus updated the slides to include at least the pointer to these new papers. The most important (in my opinion) is the derivation of the Petz transpose map from a principle of minimum change. The original slides presented in the video are still available at this link.
Fugue in D Minor for four voices (subject by Gedalge)
I wrote this while preparing for the Eighth Year Exam of Classical Composition at the Conservatory of Milan, in 1999 (or perhaps 2000?). The subject (the first four bars) is one of Gedalge’s classical treatise’s exercises (it’s the number 4). I remember it was really a pleasure to see a fugue getting together nicely, and this is one of the best I wrote. (My countersubject, in particular, functions very well…)
I am jealously preserving all my handwritten scores, but recently I also found a transcription I made in Finale (I believe that was the 1998 version; a real pain to use) and here is its MIDI rendition: enjoy! 🙂
About the logical foundations of the second law of thermodynamics
“The law that entropy always increases holds, I think, the supreme position among the laws of Nature. If someone points out to you that your pet theory of the universe is in disagreement with Maxwell’s equations – then so much the worse for Maxwell’s equations. If it is found to be contradicted by observation—well, these experimentalists do bungle things sometimes. But if your theory is found to be against the Second Law of Thermodynamics I can give you no hope; there is nothing for it to collapse in deepest humiliation.”
― Arthur Eddington, The Nature of the Physical World, Chap. 4
But why is that so? Why is the Second Law so “special” among the other laws of physics?
Simply because—as we argue in a paper recently published on Physical Review E and freely available on the arXiv—the Second Law is not so much about physics, as it is about logic and consistent reasoning. More precisely, we argue that the Second Law can be seen as the shadow of a deeper asymmetry that exists in statistical inference between prediction and retrodiction, and ultimately imposed by the consistency of the Bayes–Laplace Rule.
A little bit of background. In the past two decades, thermodynamics has undergone unprecedented progresses. These can be traced back to the developments of stochastic thermodynamics, on the one hand, and the theory of nonequilibrium fluctuations, on the other. The latter, in particular, has shown that the Second Law emerges from a more fundamental “balance relation” between a physical process and its reverse. According to such a balance relation, for example, scrambled eggs are not forbidden to unscramble spontaneously—instead, the probability of such a process is just extremely tiny, compared with that of its more familiar reverse. In turn, entropy—i.e. the thing that “no one knows what it really is”, according to the apocryphal exchange between Shannon and von Neumann—precisely is a measure of such a disparity.
In this paper we go one step further and show that the existence of a disparity is not due to some kind of “physical propensity” that irreversible processes have for unfolding in one direction more likely than in the opposite direction—an explanation that would lead to a circular argument—, but to the intrinsic asymmetry that exists between prediction and retrodiction in inferential logic. We thus conclude that the foundations of the Second Law are not to be found within physics, but one step below, at the level of logic.
A nice little piece written by CQT/NUS outreach is also available here.
Colloquium on Bayesian retrodiction in statistical physics
One month ago I gave a colloquium at the 13th Annual Symposium of the Centre for Quantum Technologies (CQT) in Singapore. I decided to speak about my recent work on the role of Bayesian retrodiction in statistical mechanics — more precisely, in the conceptual foundations underlying fluctuation relations and the second law of thermodynamics.
The preprint is available on the arXiv: https://arxiv.org/abs/2009.02849
Invited talk at AQIS 2020
Given at the Asian Quantum Information Science Conference 2020 (link).
Jaynes on thermodynamics

To understand and like thermo we need to see it, not as an example of the n-body equations of motion, but as an example of the logic of scientific inference.
in: E.T. Jaynes, “Predictive statistical mechanics” (1984)
Quantum entanglement: from basic question to technological resource
This colloquium, aimed at an audience with basic knowledge about quantum theory but not necessarily familiar with the topic, was given for the Online Colloquium Series of the School of Computational Science of the Korea Institute for Advanced Study (KIAS).
“Quantumness” always happens in time—and needs to be programmable
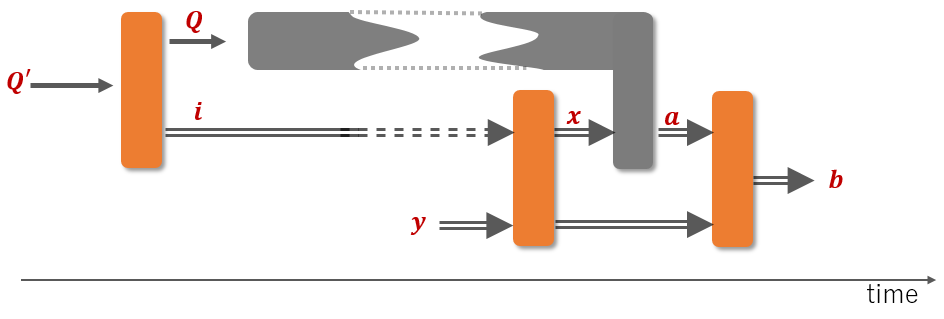
Incompatibility of quantum measurements lies at the core of nearly all quantum phenomena, from Heisenberg’s Uncertainty Principle, to the violation of Bell inequalities, and all the way up to quantum computational speed-ups. Historically, quantum incompatibility has been considered only in a qualitative sense. However, recently various resource-theoretic approaches have been proposed that aim to capture incompatibility in an operational and quantitative manner. Previous results in this direction have focused on particular subsets of quantum measurements, leaving large parts of the total picture uncharted.
A work, which I wrote together with Eric Chitambar and Wenbin Zhou and was published yesterday on Physical Review Letters, proposes the first complete solution to this problem by formulating a resource theory of measurement incompatibility that allows free convertibility among all compatible measurements. As a result, we are now able to explain quantum incompatibility in terms of quantum programmability; namely, the ability to switch on the fly between incompatible measurements is seen as a resource. From this perspective, quantum measurement incompatibility is intrinsically a dynamical phenomenon that reveals itself in time as we try to control the system.
Read about this on Physical Review Letters or, for free, on the arXiv.
Is the Heisenberg picture propagating operators “backwards in time”?
A recent arXiv post ignited an interesting discussion with students and colleagues, demonstrating once more how the Heisenberg picture in quantum mechanics can easily be misunderstood to the point of becoming almost paradoxical. Here I intend to briefly summarize what I think may be the crux of the problem (or problems). The argument below follows a discussion on the topic that I had with Masanao Ozawa few years ago; however, any error or misunderstanding in it is to be entirely attributed to me.
One-step evolutions
Suppose that we are following the evolution of a quantum system from an initial time 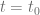


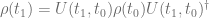
The latter is called the Schrödinger picture of the evolution. In this picture, states evolve in time, while observables (like the Hamiltonian) do not.
The Heisenberg picture is meant to do the opposite: it keeps states “freezed”, while observables evolve. It can be also understood as a “pullback” operation: very much like when one looks at a rotation from the viewpoint of vectors (Schrödinger picture) or the viewpoint of the coordinate system (Heisenberg picture).
For the two pictures to give consistent predictions, that is, ![Tr[\rho(t_1)\ H(t_0)]=Tr[\rho(t_0)\ H(t_1)]](https://s0.wp.com/latex.php?latex=Tr%5B%5Crho%28t_1%29%5C+H%28t_0%29%5D%3DTr%5B%5Crho%28t_0%29%5C+H%28t_1%29%5D&bg=ffffff&fg=5e5e5e&s=0&c=20201002)



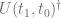

It is quite tempting at this point to interpret this by saying that “states evolve forward in time, while observables evolve backwards in time”. If only two times are considered, that seems just a curious though innocuous way of phrasing it. Indeed I have heard a lot of researchers explaining the Heisenberg picture this way. I myself would have nodded my head hearing this some years ago. However, I now see why this interpretation can be in fact very confusing, potentially leading to wrong calculations, when more than two times are considered.
Two-step evolutions: the wrong approach
Imagine now to fix three instants in times, 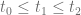
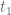

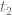
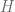

But what should be the evolution operator describing the box denoted by question marks? As the arXiv post mentioned at the beginning of this post argues, one could be tempted to say that the right evolution operator is 
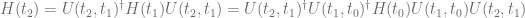
Problem is, this is of course wrong! The correct thing to do is to understand that the total evolution of the state from 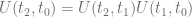

This is the correct description of 
Another, more subtle, source of confusion
We have seen how the naive “backwards in time” interpretation is wrong. However, at this point, another structure emerges that still suggests some kind of “time-reversal”. I am speaking now of the fact that, in the correct equation, that is, 
Given that the equation itself is correct, in what follows I am simply criticizing its interpretation. I would like to argue, in particular, that, even though the evolution operators act in reverse order on the observable, the Heisenberg picture should not (or, at least, need not) be interpreted or explained as “backwards in time” evolution.
The point is that
Hence, in the Heisenberg picture, the propagator of observables from

If we substitute this into the initial formula, then we indeed obtain that 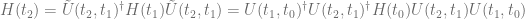

However, once written as above, it gives us a very clear understanding of what is going on in the Heisenberg picture.
Summarizing, the Heisenberg picture is indeed a pullback transformation, but a pullback that happens forward in time. After all, both Heisenberg and Schrödinger pictures provide equivalent representations of exactly the same process, which of course happens forward in time.
